WISER: multimodal variational inference for full-waveform inversion without dimensionality reduction

We present a semi-amortized variational inference framework designed for computationally feasible uncertainty quantification in 2D full-waveform inversion to explore the multimodal posterior distribution without dimensionality reduction. The framework is called WISER, short for full-Waveform variational Inference via Subsurface Extensions with Refinements. WISER leverages the power of generative artificial intelligence to perform approximate amortized inference that is low-cost albeit showing an amortization gap. This gap is closed through non-amortized refinements that make frugal use of acoustic wave physics. Case studies illustrate that WISER is capable of full-resolution, computationally feasible, and reliable uncertainty estimates of velocity models and imaged reflectivities.
1 Introduction
Full-waveform inversion (FWI) aims to estimate unknown multi-dimensional (\(\mathrm{D}\geq 2\)) velocity models, denoted as \(\mathbf{x}\), from noisy seismic data, \(\mathbf{y}\), by inverting the nonlinear forward operator, \(\mathcal{F}\), which relates \(\mathbf{x}\) and \(\mathbf{y}\) via \(\mathbf{y} = \mathcal{F}(\mathbf{x})+\boldsymbol{\epsilon}\) with \(\boldsymbol{\epsilon}\) measurement noise (Virieux and Operto 2009). FWI poses significant challenges, as it requires solving a high-dimensional, non-convex, and ill-posed inverse problem, with a computationally demanding forward operator in multiple dimensions. In addition, the inherent nonuniqueness of FWI results leads to multiple possible Earth models compatible with the observed data, underscoring the need for uncertainty quantification (UQ) to handle this multimodality.
The trade-off between accuracy and computational cost is a critical consideration in any high-dimensional inference routine with expensive forward operators (Cranmer, Brehmer, and Louppe 2020), including FWI. To circumvent the costs associated with global optimization, several approaches have attempted localized UQ (Fang et al. 2018; Keating and Innanen 2021; Izzatullah, Ravasi, and Alkhalifah 2023; Hoffmann et al. 2024) based on the Laplace approximation. However, these approaches may not capture the full complexities of multimodal parameter spaces. In contrast, a Bayesian inference approach offers a costly but comprehensive resolution of the posterior distribution, \(p(\mathbf{x}\mid\mathbf{y})\).
Bayesian inference algorithms are broadly categorized into two groups. The first, sampling-based methods, like Markov-chain Monte Carlo (McMC, Cowles and Carlin 1996), struggle with high-dimensional parameter spaces. To meet this challenge, they often rely on too restrictive low-dimensional parameterizations to reduce the number of sampling iterations (Fang, Fang, and Demanet 2020; Liang, Wellmann, and Ghattas 2023; Wei, Sun, and Sen 2023, 2024b; Wei, Sun, and Sen 2024a; Dhabaria and Singh 2024), which could bias the inference results, rendering them impractical for multi-D UQ studies especially when solutions are nonunique.
The second category, optimization-based methods, like variational inference (VI, Zhang et al. 2021), seek to approximate the posterior distribution using classes of known parameterized distributions. VI can be subdivided into amortized and non-amortized methods. Amortized VI involves a computationally intensive offline training phase, leveraging advances in generative artificial intelligence (genAI), particularly with models like conditional diffusion (Baldassari et al. 2024) and conditional normalizing flows (CNFs, Winkler et al. 2019). After training, amortized VI provides rapid sampling during inference (Siahkoohi et al. 2023; Orozco, Louboutin, et al. 2023), exemplified by the WISE framework (Yin et al. 2024) for multi-D FWI problems. However, these methods may suffer from an amortization gap — implying that the amortized networks may only deliver suboptimal inference for a single observation at inference time, particularly when trained with limited examples or when there exists a discrepancy between training and inference (Marino, Yue, and Mandt 2018). Conversely, non-amortized VI dedicates entire computational resources to the online inference (Zhao, Curtis, and Zhang 2022; Zhang et al. 2023; Zhang and Curtis 2024). They result in more accurate inference, but the costly optimization has to be carried out repeatedly for new observations, and integrating realistic priors can be challenging since the prior needs to be embedded involving density evaluations (Kruse et al. 2021).
This paper introduces WISER as a semi-amortized VI framework to facilitate computationally feasible and reliable UQ for multi-D FWI without dimensionality reduction. Building on WISE, we train CNFs for efficient, suboptimal amortized inference, but then follow up with a crucial refinement step that only needs frugal use of the forward operator and its gradient. The refinement step aligns the posterior samples with the observation during inference, effectively bridging the amortization gap and enhancing inference accuracy.
Our contributions are organized as follows. We begin by outlining WISER in Algorithm 1. We explore the algorithm by explaining amortized VI with WISE, followed by computationally feasible multi-D physics-based refinement. The performance of WISER is demonstrated through realistic synthetic 2D case studies using the Compass model (Jones et al. 2012), showcasing improvements over WISE for both in- and out-of-distribution scenarios.
2 Amortized VI with WISE (lines 1—20)
WISER starts with an offline training phase that leverages conditional generative models to approximate the posterior distribution. This is achieved by WISE (Yin et al. 2024), which involves generating a training dataset (lines 3—9 of Algorithm 1) and training the CNFs (line 11—12).
2.1 Dataset generation (lines 3—9)
We begin by drawing \(N\) velocity models from the prior distribution, denoted by \(p(\mathbf{x})\) (line 5). For each sample, \(\mathbf{x}^{(i)}\), we simulate the observed data, \(\mathbf{y}^{(i)}\), by performing the wave modeling and adding a random noise term (lines 6—7). Next, we compute common-image gathers (CIGs, Hou and Symes 2016) for each observed data with an initial smooth 1D migration-velocity model, \(\mathbf{x}_0\), which can be rather inaccurate. These CIGs, represented by \(\overline{\mathbf{y}}^{(i)}\), are produced by applying the adjoint of the extended migration operator, \(\overline{\nabla\mathcal{F}}(\mathbf{x}_0)^{\top}\), to the observed data. Using CIGs as the set of physics-informed summary statistics not only preserves information from the observed seismic data (Kroode 2023) but also enhances the training of CNFs in the next stage (Radev et al. 2020; Orozco, Siahkoohi, et al. 2023), as they help to decode the wave physics, translating prestack data to the image (subsurface-offset) domain.
2.2 Network training (lines 11—12)
CNFs are trained with pairs of velocity models and CIGs via minimization of the objective in line 12. The symbol \(f_{\boldsymbol{\theta}}\) denotes the CNFs, characterized by their network weights, \(\boldsymbol{\theta}\), and the Jacobian, \(\mathbf{J}_{f_{\boldsymbol{\theta}}}\). The term “normalizing” within CNFs implies their functionality to transform realizations of velocity models, \(\mathbf{x}^{(i)}\), into Gaussian noise from a standard multivariate normal distribution (as defined by the \(\ell_2\) norm), conditioned on the summary statistics (CIGs).
2.3 Online inference (lines 14—20)
The aforementioned data generation and CNF training procedures conclude the offline training phase. During online inference, amortized VI is enabled by leveraging the inherent invertibility of CNFs. For a given observation, \(\mathbf{y}_{\mathrm{obs}}\), the online cost is merely generation of a single set of CIGs (line 16). Subsequently, the posterior samples are generated by applying the inverse of the CNFs to Gaussian noise realizations, conditioned on these CIGs (lines 18—19)1.
3 Physics-based refinements (lines 22—32)
Consider a single observation, \(\mathbf{y}_{\mathrm{obs}}\), and its corresponding posterior samples, \(\mathbf{x}_i \sim p(\mathbf{x} \mid \overline{\mathbf{y}}_{\mathrm{obs}})\). The latent representations generated by the trained CNFs, \({\hat{\mathbf{z}}_i} = f_{\boldsymbol{\theta}^{\ast}}(\mathbf{x}_i; \overline{\mathbf{y}}_{\mathrm{obs}})\), may not conform exactly to the standard Gaussian distribution during inference. To address this issue, we follow Siahkoohi et al. (2023) to apply latent space corrections to fine-tune the trained CNFs. This involves integrating a shallower, yet invertible, network2, specifically trained to map realizations of true Gaussian noise to the corresponding latent codes, \({\hat{\mathbf{z}}_i}\). Adhering to a transfer learning approach, we maintain the weights of the trained CNFs while solely updating the weights of the shallower network by minimizing the following objective:
\[ \underset{\boldsymbol{\phi}}{\operatorname{minimize}} \quad \mathbb{E}_{\mathbf{z}\sim\mathrm{N}(\mathbf{0}, \mathbf{I})}\left[\frac{1}{2\sigma^2}\|\mathcal{F}\circ f_{\boldsymbol{\theta}^{\ast}}^{-1}\left(h_{\boldsymbol{\phi}}\left(\mathbf{z}\right);\overline{\mathbf{y}}_{\mathrm{obs}}\right)-\mathbf{y}_{\mathrm{obs}}\|_2^2 + \frac{1}{2}\|h_{\boldsymbol{\phi}}\left(\mathbf{z}\right)\|_2^2- \log\left|\det\mathbf{J}_{h_{\boldsymbol{\phi}}}\right|\right]. \tag{1}\]
Here, the refinement network, \(h_{\boldsymbol{\phi}}\), mitigates the amortization gap by adjusting the latent variable \(\mathbf{z}\) before feeding it to the inverse of the trained CNFs, \(f_{\boldsymbol{\theta}^\ast}^{-1}\). Intuitively, minimizing the first terms ties the posterior samples closer to the observed data. The second and third terms prevent the corrected latent space from being far from the Gaussian distribution, which implicitly takes advantage of the prior information existing in the amortized training phase.
Equation 1 offers a fine-tuning approach that leverages the full multi-D wave physics to refine the amortized VI framework for a single observation at inference phase. However, it introduces notable computational demands because it necessitates the coupling of the modeling operator and the networks. Specifically, every update to the network weights, \(\boldsymbol{\phi}\), requires costly wave modeling operations. Given that network training typically involves numerous iterations, these computational demands can render it impractical for realistic FWI applications.
To relieve this computational burden, we adopt a strategy from Siahkoohi, Rizzuti, and Herrmann (2020) to reformulate Equation 1 into a weak form by allowing the network output to be only weakly enforced (in an \(\ell_2\) sense) to be the corrected velocity models. The objective function for this weak formulation reads:
\[ \underset{\mathbf{x}_{1:M}, \boldsymbol{\phi}}{\operatorname{minimize}} \quad \frac{1}{M}\sum_{i=1}^{M} \left[\frac{1}{2\sigma^2}\|\mathcal{F}(\mathbf{x}_i)-\mathbf{y}_{\mathrm{obs}}\|_2^2 + \frac{1}{2\gamma^2}\|\mathbf{x}_i-f_{\boldsymbol{\theta}^{\ast}}^{-1}\left(h_{\boldsymbol{\phi}}\left(\mathbf{z}_i\right);\overline{\mathbf{y}}_{\mathrm{obs}}\right)\|_2^2 + \frac{1}{2}\|h_{\boldsymbol{\phi}}\left(\mathbf{z}_i\right)\|_2^2 - \log\left|\det\mathbf{J}_{h_{\boldsymbol{\phi}}}\right| \right]. \tag{2}\]
We strategically decouple the computationally expensive forward operator, \(\mathcal{F}\), from the more cheap-to-evaluate networks, \(f_{\boldsymbol{\theta}^\ast}\) and \(h_{\boldsymbol{\phi}}\). This is achieved in a penalty form with the assumption that the misfit between the network outputs and the posterior samples adheres to a Gaussian distribution, \(\mathrm{N}(\mathbf{0}, \gamma^2\mathbf{I})\), where \(\gamma\) is a hyperparameter dictating the trade-off between data misfit and regularization. Setting \(\gamma\) to \(0\) equates this weak formulation to the constrained formulation in Equation 1. This weak formulation also supports optimization strategies for updating the velocity models with physical constraints (Esser et al. 2018; Peters, Smithyman, and Herrmann 2019) and multiscale optimization techniques (Bunks et al. 1995).
WISER takes full computational advantage of this weak formulation by employing a nested loop structure. The outer loop is dedicated to updating \(M\) velocity models, \(\mathbf{x}_i\), through costly gradient descent steps (lines 24—27 of Algorithm 1), while the inner loop (lines 28—31) focuses on more updates (with the ADAM optimizer) to network weights, \(\boldsymbol{\phi}\), without computationally expensive physics modeling. To achieve a balance, we conduct \(\mathrm{maxiter}_2=128\) iterations in the inner loop. After refinements, WISER first evaluates the refined network on the latent variables to obtain refined latent codes. Subsequently, the amortized network uses the refined codes conditioned on the CIGs to compute the corrected posterior samples (line 34).
4 Case studies
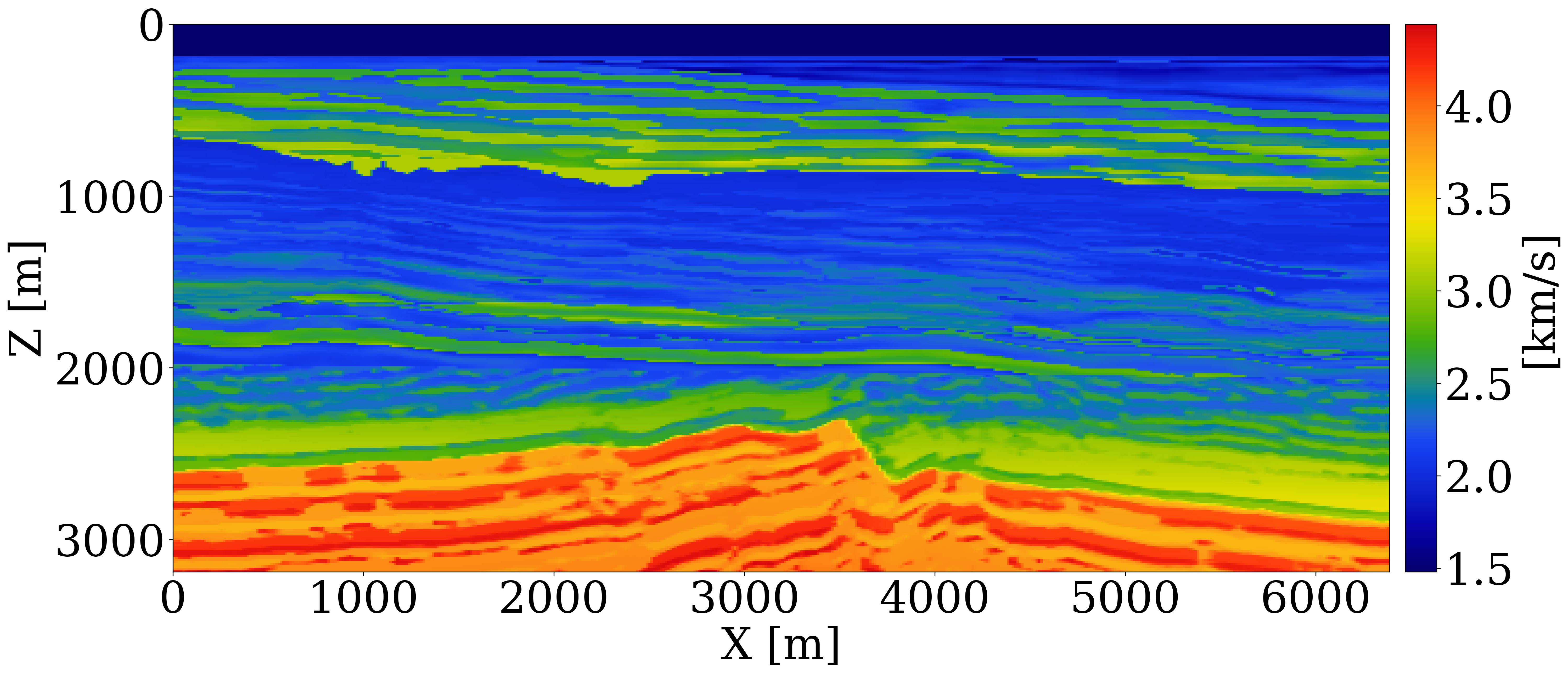
Evaluation of WISER is conducted through synthetic case studies utilizing 2D slices of the Compass model and 2D acoustic wave physics. The parameter of interest is discretized into \(512 \times 256\) gridpoints with a spatial resolution of \(12.5\,\mathrm{m}\), resulting in over \(10^5\) degrees of freedom. The forward operator, \(\mathcal{F}\), simulates acoustic data with absorbing boundaries. A Ricker wavelet with a central frequency of \(15\,\mathrm{Hz}\) and an energy cut below \(3\,\mathrm{Hz}\) is employed. We use \(512\) sources towed at \(12.5\,\mathrm{m}\) depth and \(64\) ocean-bottom nodes (OBNs) located at jittered sampled horizontal positions (Hennenfent and Herrmann 2008). We employ source-receiver reciprocity during the modeling and sensitivity calculations. The observed data, \(\mathbf{y}^{\mathrm{obs}}\), is perturbed with band-limited Gaussian noise to achieve a signal-to-noise ratio (S/N) of \(12\,\mathrm{dB}\). The training of the CNFs uses \(N=800\) pairs of velocity models and CIGs. To demonstrate WISER’s efficacy in mitigating the amortization gap, we compare results from WISE and WISER under two scenarios during inference:
- observed shot data is generated using an in-distribution velocity model with the same forward operator;
- observed shot data is produced by an out-of-distribution (OOD) velocity model and also a slightly altered forward operator.
4.1 Case 1: in distribution
The ground-truth velocity model is an unseen 2D slice from the Compass model, shown in Figure 1 (a). Following Algorithm 1, we initiate WISER by drawing \(M=16\) Gaussian noise realizations to create the initial set of \(16\) velocity models, depicted in Figure 1 (b). To minimize computational demands, stochastic gradients (Herrmann et al. 2013) are calculated in line 25 of Algorithm 1. Each particle’s gradient is estimated using only \(1\) randomly selected OBN gather from the observed data. We also add box constraints to the velocity models to restrict their range to \(1.48\) to \(4.44\,\mathrm{km/s}\). Following \(\mathrm{maxiter}_1=80\) outer iterations—equivalent to \(20\) data passes or \(2560\) PDE solves3—–we obtain the posterior samples from WISER in Figure 1 (c).

4.1.1 Observations
The conditional mean estimate (CM) from WISE lacks finer details, particularly beneath the unconformity at depths below \(2.4\,\mathrm{km}\) (in red). This is attributed to the excessive variability in structural details of the posterior samples, visible on the right panel of Figure 1 (b).
In contrast, WISER generates more consistent and accurate posterior samples. In Figure 1 (c), the right panel shows that the uncertainty from WISER is reduced below the unconformity. The upper panel illustrates that the uncertainty is more focused on the dipping events at the unconformity, highlighting areas of poor illumination.
4.1.2 Impact on imaging
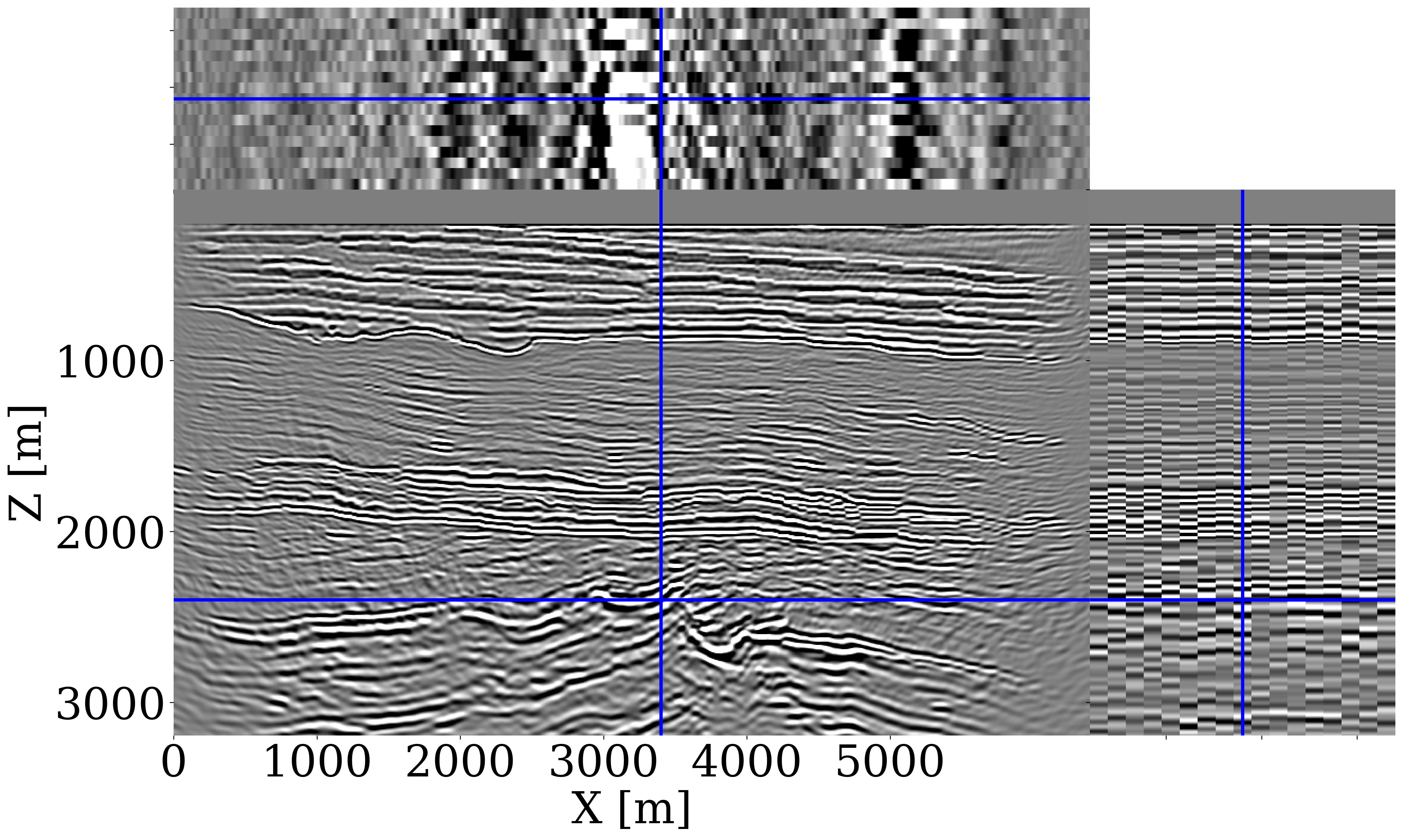
To assess the impact of uncertainty in velocity models on downstream tasks, we conduct high-frequency imaging using a Ricker wavelet with central frequency of \(30\,\mathrm{Hz}\) and compare the imaged reflectivities derived from the posterior samples of both WISE and WISER, shown in Figure 1 (d) and Figure 1 (e), respectively.
The imaged reflectivities produced by CM from WISER exhibit superior continuity and a better correlation with the CM migration-velocity model, particularly noticeable in Figure 1 (g) under the unconformity. Also, reflectivity samples produced by WISER demonstrate improved alignment among themselves compared to those produced by WISE. In addition, notable vertical shifts observed in the imaged reflectivities from WISE to WISER indicate significant adjustments in the positioning of subsurface reflectors, underlining the necessity of the refinement procedure for precisely estimating migration-velocity models that locate subsurface reflectors more accurately.
4.2 Case 2: out of distribution
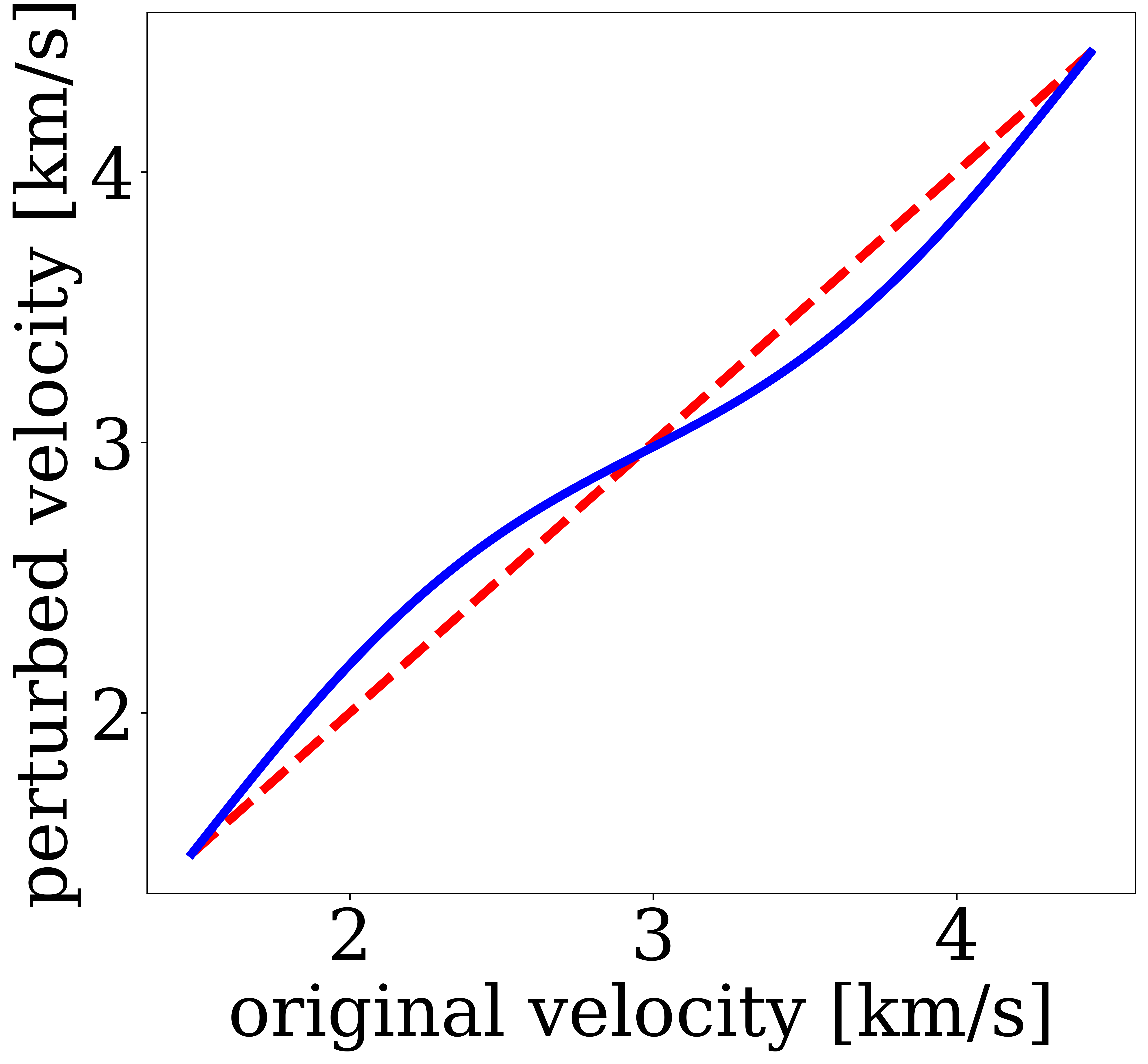
To test the robustness and adaptability of WISER when faced with unexpected variations at inference, we also evaluate WISER’s performance under OOD scenarios. We introduce alterations to the velocity model depicted in Figure 1 (a) through an elementwise perturbation shown in Figure 2 (a). This manipulation modifies the velocity values across different depth levels, resulting in a significant shift in their statistical distribution, illustrated in Figure 2 (b). We use the perturbed velocity as the unseen ground-truth velocity model in this case study, shown in Figure 2 (c). To further expand the amortization gap, we modify the encoding of the forward operator by introducing a higher amplitude of band-limited Gaussian noise (S/N \(0\,\mathrm{dB}\)).
These complexities present substantial challenges for WISE, leading to biased inference results as depicted in Figure 2 (d). The yellow histograms in Figure 2 (b) show that the velocity values of the posterior samples from WISE closely resemble those of the original velocity model, despite the different distribution of the ground-truth velocity model. This indicates that WISE tends to incorporate an inductive bias from the training samples. In WISER, we conduct \(\mathrm{maxiter}_1=160\) outer iterations, using \(M=16\) particles and \(1\) OBN per gradient. We also employ the frequency continuation method (Bunks et al. 1995) to compute the gradient in line 25 of Algorithm 1, transitioning gradually from low-frequency to high-frequency data. This results in \(40\) datapasses or \(5120\) PDE solves in total.








4.2.1 Observations
WISER produces more accurate posterior samples shown in Figure 2 (e). Furthermore, the statistical distribution of the velocity values in the WISER posterior samples (green histogram in Figure 2 (b)) aligns better with the distribution of the unseen ground-truth velocity values (blue histogram in Figure 2 (b)), demonstrating WISER’s robustness against potential distribution shifts during inference.
To further showcase WISER’s robustness under severe measurement noise, we compare a posterior sample from WISER (Figure 2 (k)) to a velocity model estimated by FWI (Figure 2 (j)), derived by minimizing only the data likelihood (the first term in line 25 of Algorithm 1), while starting from the same initial model as WISER. The FWI result is significantly impacted by noise, while the posterior samples from WISER remain relatively noise-free and capture all pertinent geological structures.
4.2.2 Impact on imaging
The imaging results from WISE (Figure 2 (f)) and WISER (Figure 2 (g)) reveal noticeable discrepancies in quality. The CM migration-velocity model from WISE leads to discontinuities in the imaged reflectivities, particularly at the horizontal layer around \(1.8\,\mathrm{km}\) depth and more so below the unconformity. In contrast, the CM from WISER significantly improves the continuity of the imaged reflectivities across the entire seismic section. The imaged reflectivity samples from WISER not only show better consistency among themselves but also align more accurately with the estimated CM migration-velocity model, particularly visible in Figure 2 (i).
5 Discussion and conclusions
The primary contribution of WISER is to leverage both genAI and physics to achieve a semi-amortized VI framework for scalable (\(\mathrm{D}\geq 2\)) and reliable UQ for FWI even in situations where local approximations are unsuitable. At its core, WISER harnesses the strengths of both amortized and non-amortized VI: the amortized posterior obtained through offline training provides a low-fidelity but fast mapping, and the physics-based refinements offer reliable and accurate inference. Both approaches benefit from information preservation exhibited by CIGs, rendering our inference successful where conventional FWI fails due to cycle skipping.
Compared to McMC methods that rely on low-dimensional parameterizations, WISER does not impose intrinsic dimensionality reductions or simplifications of the forward model. Therefore, WISER is capable of delivering full-resolution UQ for realistic multi-D FWI problems. CNFs are primed for large-scale 3D inversion thanks to their invertibility, which allows for memory-efficient training and inference (Orozco, Witte, et al. 2023).
Compared to non-amortized VI methods, WISER also requires significantly less computational resources during inference. This is because WISE, as a precursor of WISER, already provides near-accurate posterior samples, making the refinement procedure computationally feasible. Zhang et al. (2023) show that non-amortized VI, without access to realistic prior information, requires \(\mathrm{O}(10^6)\) to \(\mathrm{O}(10^8)\) PDE solves, while WISER only needs \(\mathrm{O}(10^3)\) PDE solves. Apart from the computational cost reduction, WISER ensures that the posterior samples realistically resemble Earth models, thanks to the integration of the conditional prior information from WISE. Contrary to non-amortized VI, which needs density evaluations to embed the prior (i.e., \(p(\mathbf{x})\) in line 5 of Algorithm 1) to produce realistic Earth models, WISER only needs access to samples of the prior distribution (i.e., \(\mathbf{x}^{(i)}\) in line 5).
Opportunities for future research remain. Although case 2 demonstrates the robustness of WISER concerning OOD issues, these issues could be fundamentally addressed by diversifying the training set of WISE through a foundation model (Sheng et al. 2023). Also, our OOD case study has not yet explored scenarios where the likelihood term is more pathologically misspecified, such as the presence of unremoved shear wave energy outside the range of the forward operator, which calls for further investigations. Our approach will also benefit from calibration of the estimated posterior on which the authors report elsewhere, including application of WISE(R) in 3D.
In conclusion, this paper sets the stage for deploying genAI models to facilitate high-dimensional Bayesian inference with computationally intensive multi-D forward operators. Deep learning and AI have been criticized for their reliance on realistic training samples, but WISER alleviates this reliance and still offers computationally feasible and reliable inference through a blend of offline training and online frugal physics-based refinements, preparing our approach for large 3D deployment.
6 References
Footnotes
We slightly abuse the notation to assume \(h_{\boldsymbol{\phi}}\) as an identity operator here.↩︎
For linear inverse problems in seismic imaging, Siahkoohi et al. (2023) show that an elementwise scaling and shift mechanism is adequate to bridge the gap. However, given the complex, non-convex nature of FWI, we employ \(h_{\boldsymbol{\phi}}\) as a generic invertible network.↩︎
1 PDE solve means solving the wave equation for a single source. A gradient requires 2 PDE solves (forward and adjoint).↩︎