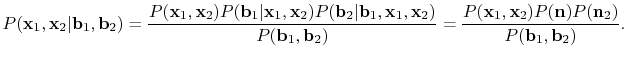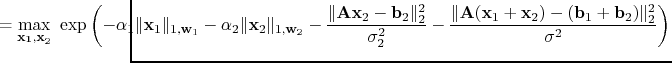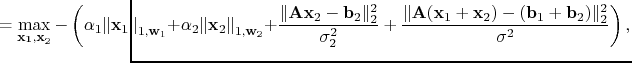Given the above formulation of the forward model, ( cf.
Equation 3), we now derive conditional probabilities for
the unknown curvelet coefficient vectors, which we initially assume to
be given by realizations of two independent random processes with
weighted Laplacian-type probability density functions. Such a choice
serves as a sparsity-promoting prior (see
e.g. Li et al. (2004); Zibulevsky and Pearlmutter (2001), and
Taylor et al. (1979); Oldenburg et al. (1981); Ulrych and Walker (1982) in the geophysical literature),
and is consistent with the high compression rates that curvelets
attain on seismic data
(Herrmann et al., 2007a; Candes et al., 2006; Hennenfent and Herrmann, 2006). Given the
SRME predictions--i.e.,
and
, our goal
is to estimate the curvelet coefficients for the two signal
components--i.e.,
and
. Probabilistically, this means that our objective is to
find the vectors
and
that maximize the
conditional probability
. In other words, using Bayes' rule we need to maximize
(4)
Since both
and
are known, we try to find
and
, the curvelet coefficients for the
primaries and multiples, that maximize the posterior probability in
Equation 4 under the assumptions: (i)
and
are independent white Gaussian noise vectors with
possibly different variances as described above, and (ii)
and
have weighted Laplacian prior
distributions. More precisely,
and
solve the optimization problem
(5)
yielding estimates
for the
primaries, and
for the
multiples. With appropriate rescaling, Equation 5 reduces to
with
(6)
Here
is the weighted
-norm of
the curvelet coefficients
(and
is the
index set for the curvelet coefficients). Heuristically, the
parameters
and
control the tradeoff between
the sparsity of the coefficient vectors and the misfit with respect to
the SRME-predictions (the total data and the multiple predictions). On
the other hand,
controls the tradeoff between the confidence in
the total data and in the SRME-predicted multiples.
Bayesian wavefield separation by transform-domain sparsity
promotion