![]()
![]()
Abstract
Uncertainty quantification provides quantitative measures on the reliability of candidate solutions of ill-posed inverse problems. Due to their sequential nature, Monte Carlo sampling methods require large numbers of sampling steps for accurate Bayesian inference and are often computationally infeasible for large-scale inverse problems, such as seismic imaging. Our main contribution is a data-driven variational inference approach where we train a normalizing flow (NF), a type of invertible neural net, capable of cheaply sampling the posterior distribution given previously unseen seismic data from neighboring surveys. To arrive at this result, we train the NF on pairs of low- and high-fidelity migrated images. In our numerical example, we obtain high-fidelity images from the Parihaka dataset and low-fidelity images are derived from these images through the process of demigration, followed by adding noise and migration. During inference, given shot records from a new neighboring seismic survey, we first compute the reverse-time migration image. Next, by feeding this low-fidelity migrated image to the NF we gain access to samples from the posterior distribution virtually for free. We use these samples to compute a high-fidelity image including a first assessment of the image’s reliability. To our knowledge, this is the first attempt to train a conditional network on what we know from neighboring images to improve the current image and assess its reliability.
Introduction
Seismic imaging is challenged by noise and a non-trivial null-space due to bandwidth and aperture limitations. These challenges lead to solution non-uniqueness where different images may fit the data equally well. Solution non-uniqueness can be characterized via a distribution over the solution space that assigns probabilities to different estimates—i.e., the posterior distribution (Tarantola, 2005). Due to the high-dimensionality of seismic images, posterior inference often requires high-dimensional sampling, for instance via Markov chain Monte Carlo (MCMC, Robert and Casella, 2004) techniques. MCMC methods sample the posterior distribution via a series of random walks in the probability space where the posterior probability density function (PDF) needs to be evaluated or approximated at each step—e.g., via stochastic gradient Langevin dynamics (Welling and Teh, 2011). These sampling methods typically require many steps to traverse the probability space (Malinverno and Briggs, 2004; Malinverno and Parker, 2006; Martin et al., 2012; Ray et al., 2017; Fang et al., 2018; Stuart et al., 2019; Z. Zhao and Sen, 2019; Kotsi et al., 2020), which fundamentally limits their applicability to large-scale problems due to costs associated with the forward operator (Curtis and Lomax, 2001; Herrmann et al., 2019; A. Siahkoohi et al., 2020; Siahkoohi et al., 2020a). Alternatively, variational inference methods (Jordan et al., 1999) approximate the posterior distribution with a parametric and easy-to-sample distribution. By virtue of this approximation, sampling is turned into an optimization problem where the parameters are tuned to minimize the “distance” between the parametric and posterior distributions. After optimization, this easy-to-sample distribution is used to conduct Bayesian inference. As discussed by Blei et al. (2017), variational-inference based methods are known to have computational advantages over MCMC in high-dimensional problems.
In this paper, we take a variational inference approach to seismic imaging and use a normalizing flow (NF, Rezende and Mohamed, 2015) as a parametric function to approximate the posterior distribution. NFs are a special type of invertible neural nets (Dinh et al., 2016; Lensink et al., 2019; Kruse et al., 2019) capable of approximating complicated functions—e.g., non-Gaussian PDFs. After training, NFs cheaply sample the distribution of interest and estimate its PDF. The latter property sets NFs apart from generative adversarial nets (GANs, Goodfellow et al., 2014) since GANs only provide samples from the distribution of interest and are incapable of explicitly representing densities by design (Goodfellow et al., 2014). Despite this disadvantage, GANs have been used successfully to carry out stochastic waveform inversions with the Metropolis-adjusted Langevin algorithm (Mosser et al., 2020). Contrary to GANs, NFs can be simply trained via the maximum-likelihood estimation method (Rezende and Mohamed, 2015), which is asymptotically consistent and efficient (Bishop, 2006). On the other hand, training GANs typically involves a min-max optimization that might lead to unstable training (Arjovsky et al., 2017). Finally, the invertibility of NFs allows for memory-efficient training since the intermediate state variables do not need to be stored (Putzky and Welling, 2019; B. Peters and Haber, 2020; P. Witte et al., 2021).
We use a data-driven approach for training the NF to take maximum advantage of available data in the form of low- and high-fidelity migrated images. One way of creating training data is to pair high-fidelity least-squares migration images with low-fidelity reverse-time migration images from nearby surveys. In this work, we mimic this choice by pairing high-fidelity images from the Parihaka dataset (WesternGeco., 2012) with low-fidelity images obtained via the process of demigration, followed by adding noise and migration. This approach circumvents the challenges of explicitly choosing a prior distribution that captures the true heterogeneity exhibited by the Earth’s subsurface. Moreover, the NF trained via this method is not specific to one seismic survey, but thanks to the NF’s ability to generalize can be used to characterize the posterior distribution associated with a previously unseen seismic survey, which is in some sense close—e.g., data from a neighboring survey area. Finally, this approach, unlike MCMC methods, does not involve repeated evaluations of the forward operator, however, by providing the reverse-time migrated image to the NF we implicitly capture the likelihood and prior in our learned posterior distribution. To our knowledge, this is the first normalizing-flow based scalable attempt to cheaply sample from the seismic imaging posterior distribution given previously unseen seismic data.
In the context of variational inference for inverse problems with expensive forward operators, Stein variational gradient descent (Liu, 2017) is used to iteratively push samples from the prior to the posterior distribution to tackle full-waveform inversion (Zhang and Curtis, 2020a) and seismic tomography (Zhang and Curtis, 2020b). Rizzuti et al. (2020) and X. Zhao et al. (2020) both independently proposed a physics-based variational inference approach that approximates the posterior distribution with a distribution represented by a NF. While this approach does not require training data, it does need choosing a prior and repeated computationally expensive evaluations of the forward operator and the adjoint of its Jacobian (migration). However, there are indications that this formulation can be faster and easier to scale to large-scale problems compared to MCMC methods (X. Zhao et al., 2020). Motivated by Kruse et al. (2019), Siahkoohi et al. (2021) take this approach a step further by proposing a two-stage multifidelity approach where during the first stage a conditional NF is trained on available pairs of low- and high-fidelity images. This pretrained NF is subsequently fine tuned during an optional second physics-based variational inference stage, which is tailored to the physics of the specific imaging problem at hand. In this work, we focus on the first stage because it is computational cheap and provides a rudimentary assessment of the image’s reliability. Moreover, since the first stage entails training over low- and high-fidelity image pairs of related imaging problems, it can serve as a warm start for the optional second more accurate physics-based inference stage (Siahkoohi et al., 2020b, 2021), greatly reducing its costs. In related data-driven GAN-based approaches, Adler and Öktem (2018) and Kovachki et al. (2020) also train neural nets capable of sampling from the posterior distribution given new data. Instead of adhering to GANs, we rely on NFs, which are easier to train and have a much more limited memory footprint during the training phase, making them applicable to larger-scale problems.
In the following section, we first briefly introduce variational inference and mathematically state the foundations of NFs. Next, we describe our proposed normalizing-flow based formulation for seismic imaging and Bayesian inference. We conclude by showcasing our approach on a “quasi” real example that derives from 2D subsets of the Parihaka dataset.
Variational inference
At its core, the method we are proposing characterizes multivariate distributions given access to samples from these distributions only. Variational inference provides the statistical framework for this and involves the problem of approximating a distribution of interest \(p\) with a parametric distribution \(q\), represented in our case by a NF. This approximation is typically achieved by minimizing the Kullback-Leibler (KL) divergence between \(q\) and \(p\). The KL divergence offers a distance metric for distributions and can be explained as the cross-entropy of distribution \(p\) relative to distribution \(q\) minus the entropy of distribution \(q\). During variational inference, the KL divergence is minimized with respect to distribution \(q\). By design, \(q\) is typically chosen to be easy—i.e., computationally cheap, to sample from. As a result, after optimization, we can cheaply sample from the distribution \(p\) by sampling \(q\) instead. Next, we introduce NFs as a way to parameterize distribution \(q\).
Normalizing flows
A NF \(T_{\rw} : {X} \rightarrow {Z}\), parameterized by the NF weights \(\bw\), is an invertible neural net—i.e., it has a closed-from and exact inverse (up to numerical precision), with the goal of mapping inputs \(\bx \in {X}\) sampled from the distribution of interest, \(\bx \sim p(\bx)\), into samples from the Gaussian distribution \(\bz \sim p_{\rz}(\bz)\), where \(\bz \in {Z}\) and \(p_{\rz} (\bz) := \mathrm{N} (\bz \mid \mathbf{0}, \mathbf{I})\). In other words, given samples \(\{\bx^{(i)}\}_{i=1}^n \sim p(\bx)\), the parameters \(\bw\) are optimized so that the KL divergence between \(q_{\rw}\) and \(p_z\) is minimized, where \(q_{\rw}\) is the distribution of the NF’s output when \(\bx \sim p(\bx)\) are fed as input. This mapping is useful because after training we can sample from \(p(\bx)\) by simply inputting Gaussian samples \(\bz \sim p_{\rz}(\bz)\) into the inverted network, \(T_{\rw}^{-1}\), provided that \(q_{\rw}\) approximates \(p_z\) well (Rezende and Mohamed, 2015). Given samples \(\{\bx^{(i)}\}_{i=1}^n\) from the unknown distribution, minimizing the KL divergence between \(q_{\rw}\) and \(p_z\) leads to the following optimization problem for training the NF \(T_{\rw}\) (Rezende and Mohamed, 2015): \[ \begin{equation} \mathop{\rm min}_{\bw}\, \frac{1}{n} \sum_{i=1}^n \Big[ \frac{1}{2}\big\| T_{\rw} (\bx^{(i)}) \big\|^2_2 - \log \Big | \det \nabla_{\rx} T_{\rw} (\bx^{(i)}) \Big | \Big]. \label{NF-training} \end{equation} \] In the above objective, the \(\ell_2\)-norm on \(T_w\) imposes a Gaussian distribution on the network output, which is what a NF is designed to do—i.e. to Gaussianize the input, \(\bx^{(i)}\). The second term involving \(\det \nabla_{\rx} T_{\rw} (\bx)\) regularizes the entropy of \(q_{\rw}\), which avoids \(T_w (\bx)\) from producing a trivial output—i.e., \(T_w (\bx) := \mathbf{0}\). The extra costs of computing \(\det \nabla_{\rx} T_{\rw} (\bx)\) and its gradient are negligible due to the special design of invertible nets (Dinh et al., 2016). We solve the optimization problem in Equation \(\ref{NF-training}\) via stochastic optimization where at each iteration the objective is approximated via randomly selected (without replacement) training samples \(\bx^{(i)}\). In addition to sampling from \(p(\bx)\) after training, we can also use the change-of-variables formula (Villani, 2009) to cheaply estimate \(p(\bx)\) for a given \(\bx\) by \(p (\bx) \approx p_{\rz} (T_{\rw} (\bx))\, \Big | \det \nabla_{\rx} T_{\rw} (\bx) \Big |\). In cases where we only have access to samples from the prior distribution, this relation provides an expression for the prior PDF that can be used in inverse problems involving estimating \(\bx\).
Posterior inference with conditional NFs
Our ultimate goal is to capture the posterior distribution associated with inverse problems involving computationally expensive and possibly nonlinear forward operators, \(F: X \rightarrow Y\), with the forward model, \(\by = F (\bx) + \mathbf{n}\). Here, \(\bx \in X\) represents the unknown model, \(\by \in Y\) the observed data, and \(\mathbf{n}\) possibly non-Gaussian noise. Following Kruse et al. (2019), NFs can be adapted to sample from the posterior distribution, \(p(\bx \mid \by)\) given previously unseen data \(\by\). NFs capable of generating samples from conditional distributions can be defined by imposing a block-triangular structure on \(T_{\rw} : Y \times X \rightarrow Z \times Z\), which according to Kruse et al. (2019) leads to the following NF structure: \[ \begin{equation} \begin{split} T_{\rw} (\by, \bx) =\begin{bmatrix} T_{\rw_1} (\by) \\[4pt] T_{\rw_2} (\by, \bx) \end{bmatrix}, \ \bw = \begin{bmatrix} \bw_1 \\ \bw_2 \end{bmatrix}. \end{split} \label{block-triangular} \end{equation} \] In words, Equation \(\ref{block-triangular}\) describes \(T_{\rw}\) as a NF that maps the joint random variable \((\by, \bx)\) into two Gaussian random vectors, where the first output is only a function of \(\by\). As in Equation \(\ref{NF-training}\), this conditional NF can be trained given training pairs, \(\{\by^{(i)}, \bx^{(i)}\}_{i=1}^n\), by minimizing the following objective: \[ \begin{equation} \mathop{\rm min}_{\bw}\, \frac{1}{n} \sum_{i=1}^n \Big[ \frac{1}{2}\big\| T_{\rw} (\by^{(i)}, \bx^{(i)}) \big\|^2_2 - \log \Big | \det \nabla_{(\ry, \rx)} T_{\rw} (\by^{(i)}, \bx^{(i)}) \Big | \Big]. \label{NF-training-cond} \end{equation} \] This block-diagonal construction lets us sample from the posterior distribution via (Marzouk et al., 2016; Kruse et al., 2019) \[ \begin{equation} T_{\rw_2}^{-1} \big( T_{\rw_1} (\by), \bz \big) \sim p(\bx \mid \by), \quad \bz \sim p_{\rz}(\bz). \label{cond-sampling} \end{equation} \] According to this expression, samples from the posterior are drawn by first by feeding the data, \(\by\), to \(T_{\rw_1}\). Next, posterior samples are obtained by feeding \(T_{\rw_1} (\by)\) and Gaussian samples \(\bz \sim p_{\rz}(\bz)\) into the inverse network, \(T_{\rw_2}^{-1}\). These Gaussian samples can be considered as realizations of the posterior in the latent space. Compared to methods such as MCMC, this sampling procedure does not involve the forward operator and is therefore extremely fast and computationally cheap. Given samples generated with Equation \(\ref{cond-sampling}\), we approximate the conditional mean and point-wise standard deviation point-estimators via \[ \begin{equation} \boldsymbol{\mu} = \mathbb{E} \big [ \bx \mid \by \big ], \quad \boldsymbol{\sigma}^2 = \mathbb{E} \big[ \left (\bx - \boldsymbol{\mu} \right ) ^{\circ 2} \mid \by \big ], \label{point-est} \end{equation} \] where \(^{\circ 2}\) represents elementwise power of two and the expectations can be approximated with sample means.
Imaging with conditional NFs
Seismic imaging is the problem of estimating the short-wavelength squared-slowness perturbation model of the Earth’s subsurface given noisy observed seismic data and a kinematically accurate background velocity model. We cast seismic imaging into the deep-learning based framework described in the previous section to limit the computational burden of high-dimensional posterior inference. To achieve this, we choose \(\bx\) to represent the high-fidelity migrated image and \(\by\) the corresponding low-fidelity reverse-time migrated image obtained by the process of demigration, followed by adding noise and migration. With this choice, the prior information in this technique comes from different realizations of high-fidelity migrated images provided in training pairs \((\by^{(i)}, \bx^{(i)}), \ i=1,\ldots,n\), obtained from neighboring surveys. We train the NF by solving the optimization problem in Equation \(\ref{NF-training-cond}\) while using the block-triangular structure (Equation \(\ref{block-triangular}\)). This yields a conditional NF that provides cheap, fast, and forward-operator free samples from the imaging posterior distribution via Equation \(\ref{cond-sampling}\). We use these samples to obtain a high-fidelity image including a first assessment of its uncertainty.
Numerical experiments
We propose a “quasi” real example in which we generate synthetic data by applying the linearized Born scattering operator to \(4750\) 2D sections with size \(3075\, \mathrm{m} \times 5120\, \mathrm{m}\) extracted from the real Kirchhoff migrated Parihaka dataset. We consider a \(12.5\, \mathrm{m}\) vertical and \(20\, \mathrm{m}\) horizontal grid spacing, and we augment a \(125\, \mathrm{m}\) water column on top of these models to limit the near source imaging artifacts. We parameterize the linearized Born scattering operator via a made up smooth background squared-slowness model. To ensure good coverage, we simulate \(102\) shot records with a source spacing of \(50\, \mathrm{m}\). Each shot is recorded for two seconds with \(204\) fixed receivers sampled at \(25\, \mathrm{m}\) spread on top of the model. The source is a Ricker wavelet with a central frequency of \(30\, \mathrm{Hz}\). To mimic a more realistic imaging scenario, we add band-limited noise to the shot records, where the noise is obtained by filtering white noise with the source wavelet. We create training pairs \((\by^{(i)}, \bx^{(i)}), \ i=1,\ldots,4750\), by first simulating noisy seismic data according to the above mentioned acquisition design for all \(\bx^{(i)}\). Next, we obtain \(\by^{(i)}\) by applying reverse-time-migration to the obtained data for each model \(\bx^{(i)}\). We train \(T_w\) according to the objective function in Equation \(\ref{NF-training-cond}\) with the Adam (Kingma and Ba, 2014) stochastic optimization method with batch size \(16\) for \(100\) passes over the training dataset (epochs). We use an initial stepsize of \(10^{-4}\) and multiply it by \(0.9\) every two epochs.
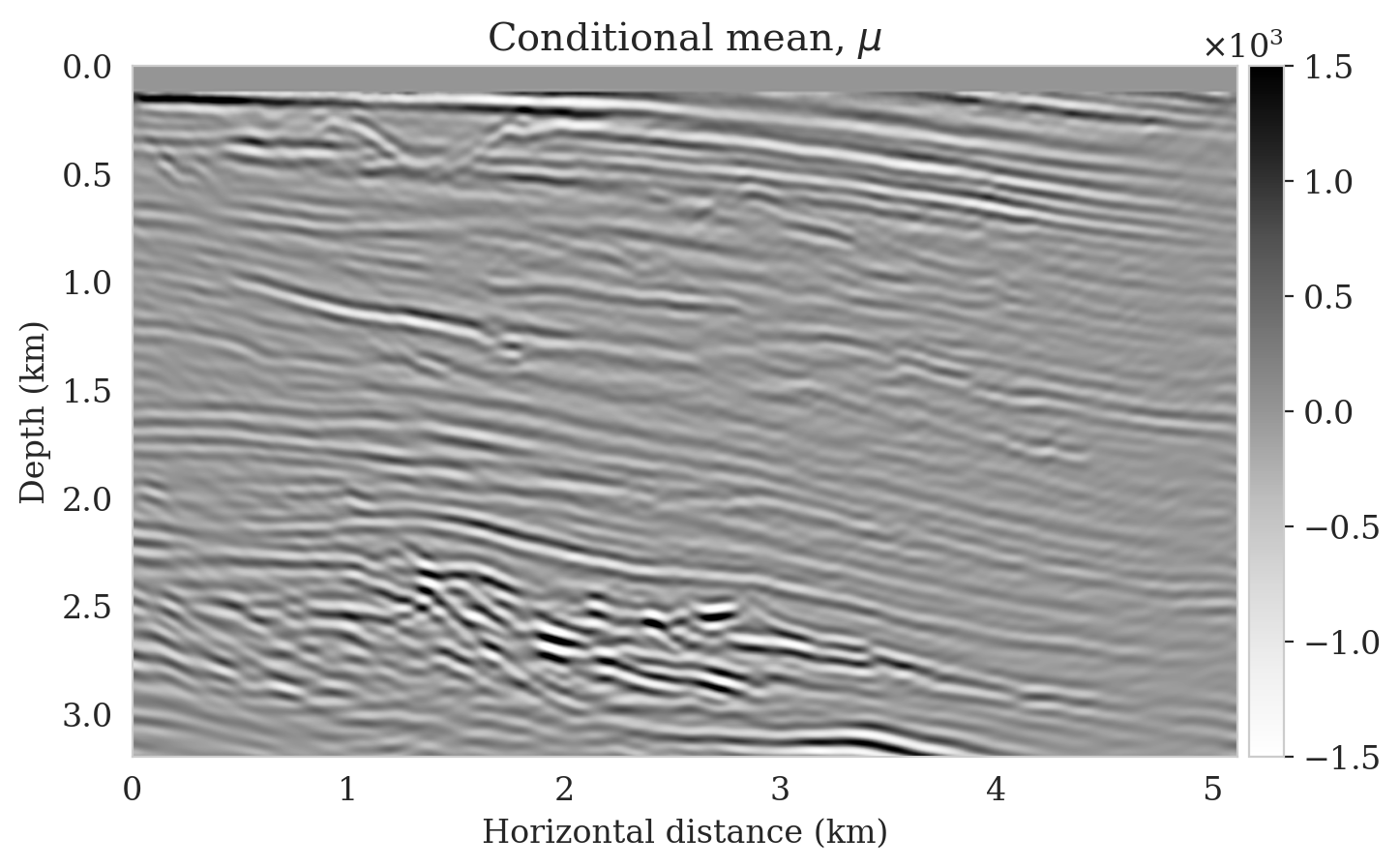
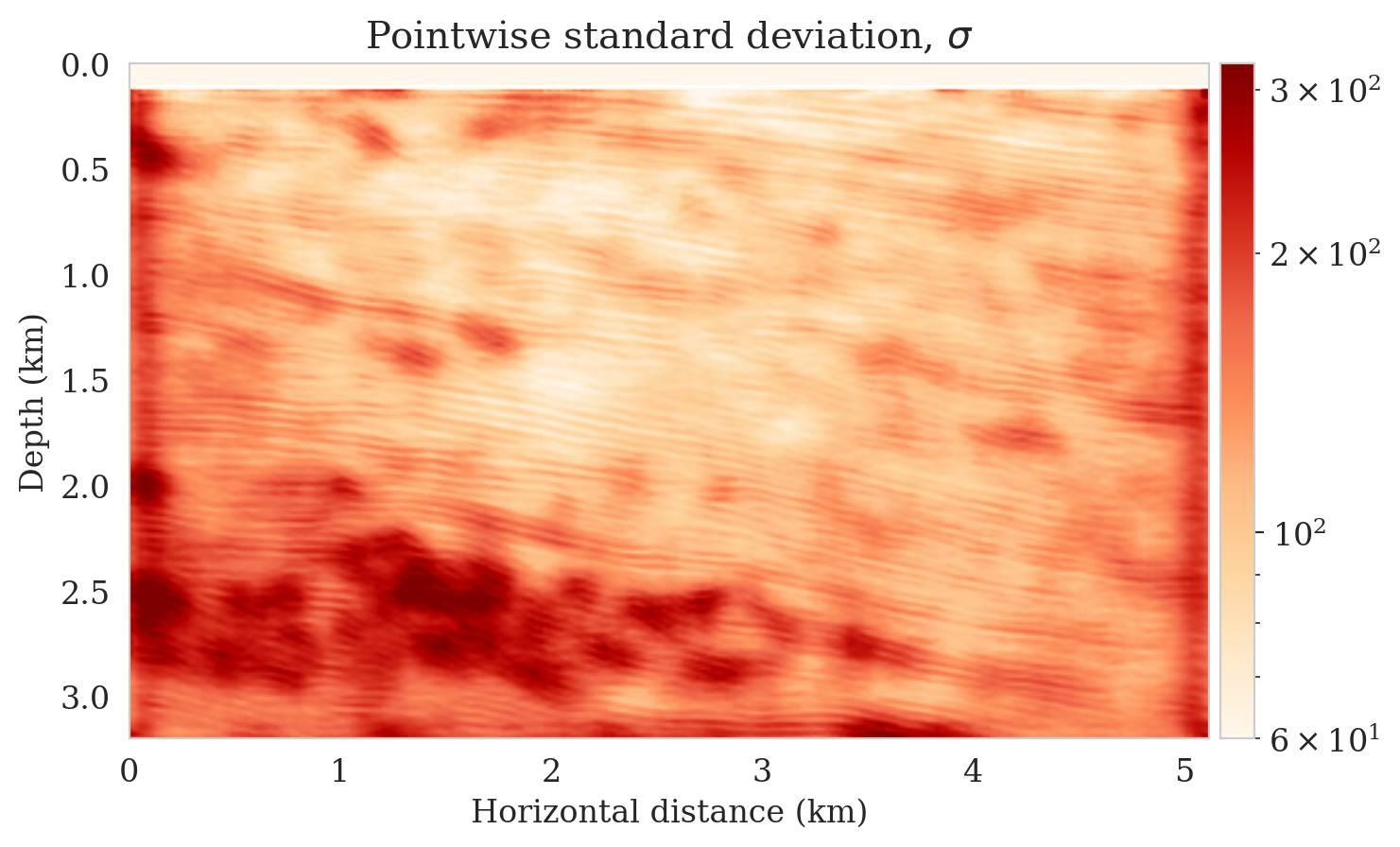
After training, we simulate noisy seismic data for a previously unseen perturbation model extracted from the Parihaka dataset, shown in Figure 1a. The corresponding low-fidelity reverse-time migrated image is shown in Figure 1b. Given this image, we use Equation \(\ref{cond-sampling}\) to generate \(1000\) random samples \(p(\bx \mid \by)\) at a negligible cost. Two of these samples are shown in Figures 1c and 1d. With these \(1000\) samples, we also estimate the conditional mean (Figure 1e) and pointwise standard deviation (Figure 1f). Because of its reported (Anderson and Moore, 1979) statistical robustness, we use the conditional mean as an estimate for the high-fidelity image. This estimate includes pointwise standard deviations that serve as an assessment of the uncertainty. From Figure 1, we observe that the overall amplitudes are well recovered by the conditional mean estimate, which includes partially recovered reflectors in badly illuminated areas close to the boundaries. Although the reconstructions are not perfect, they significantly improve upon the reverse-time migrations estimate. As expected, the pointwise standard deviation in Figure 1f indicates that we have the most uncertainty in areas of complex geology—e.g., near channels and tortuous reflectors, and in areas with a relatively poor illumination (deep and close to boundaries). The areas with large uncertainty align with difficult-to-image parts of the model.
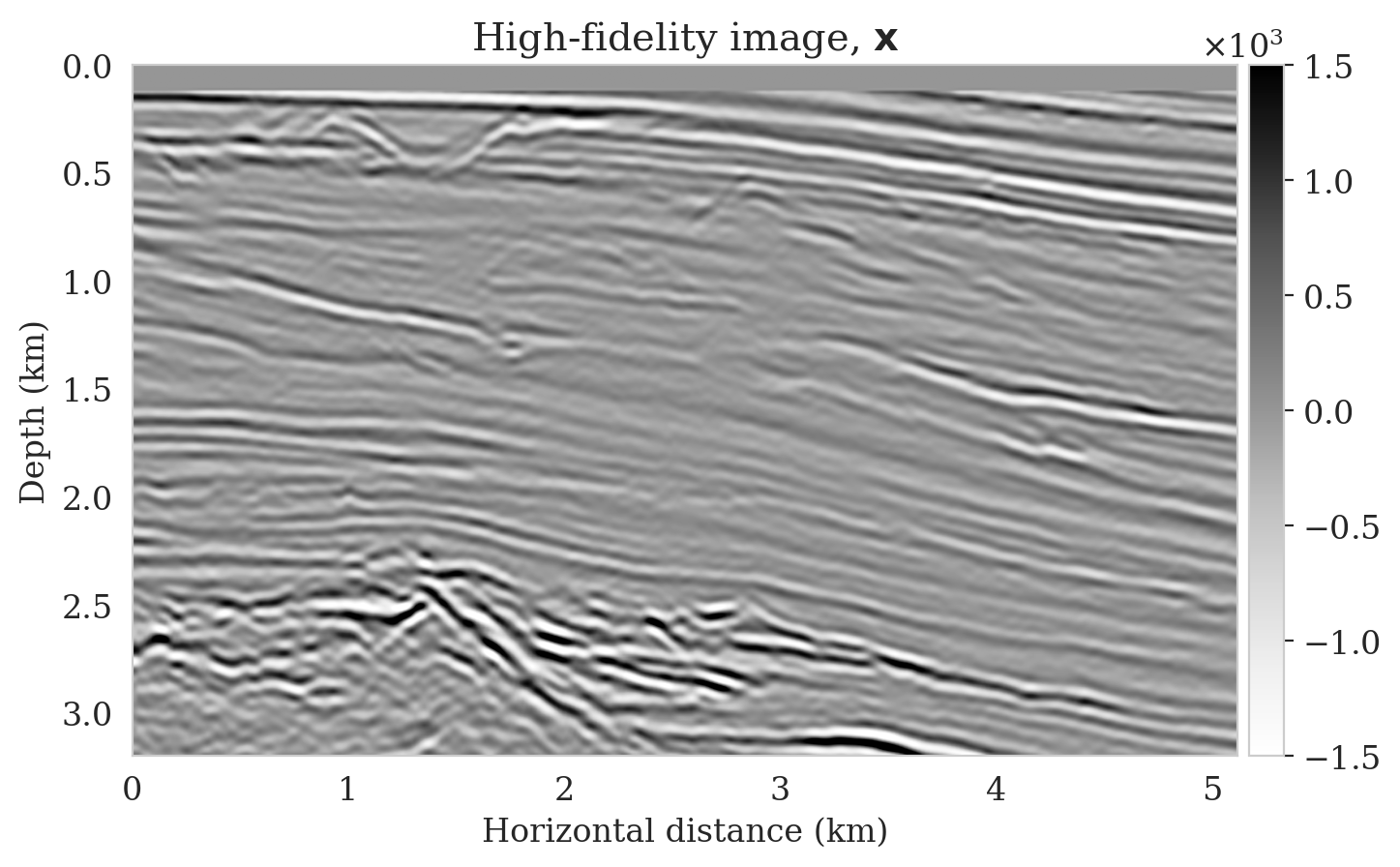
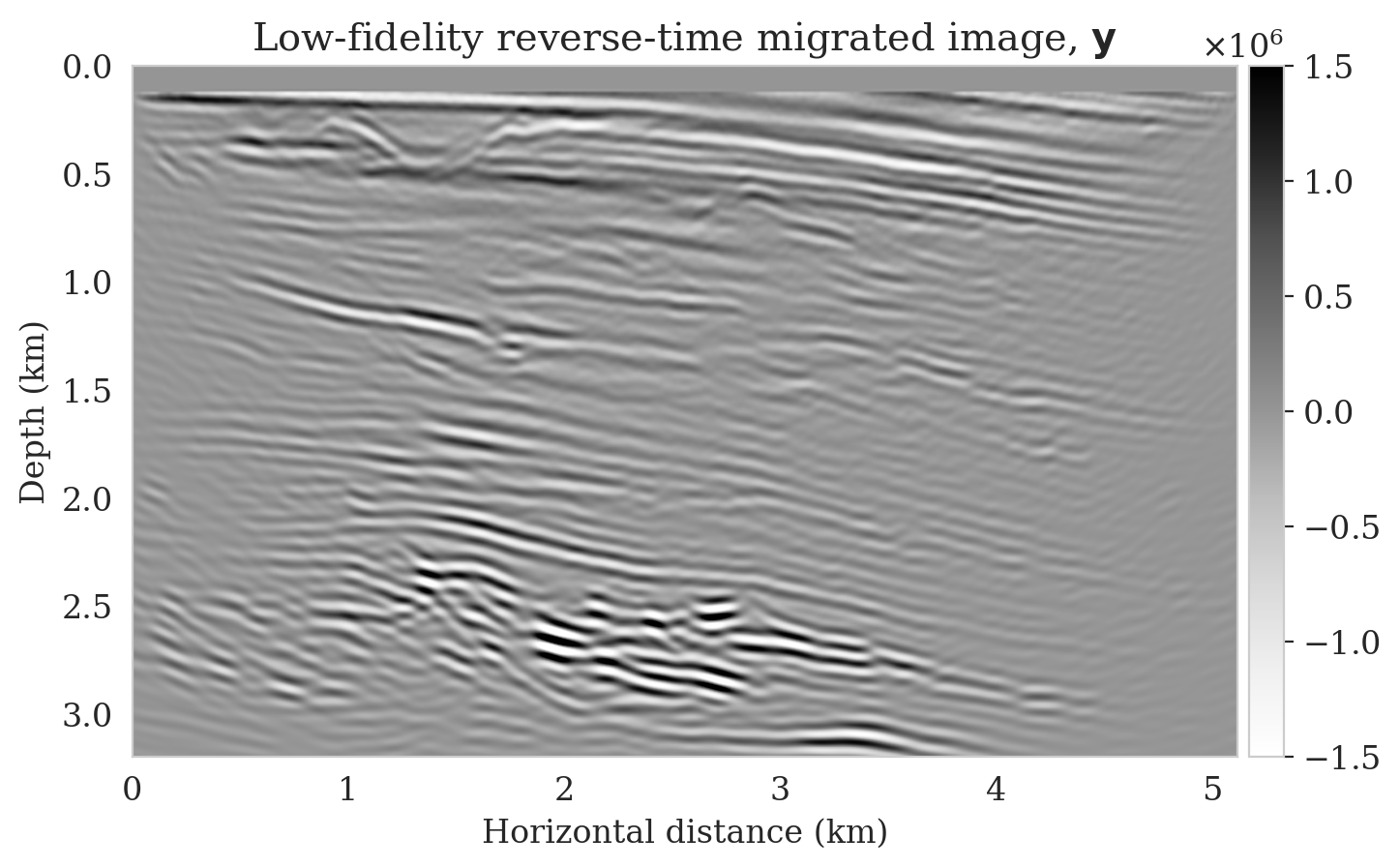
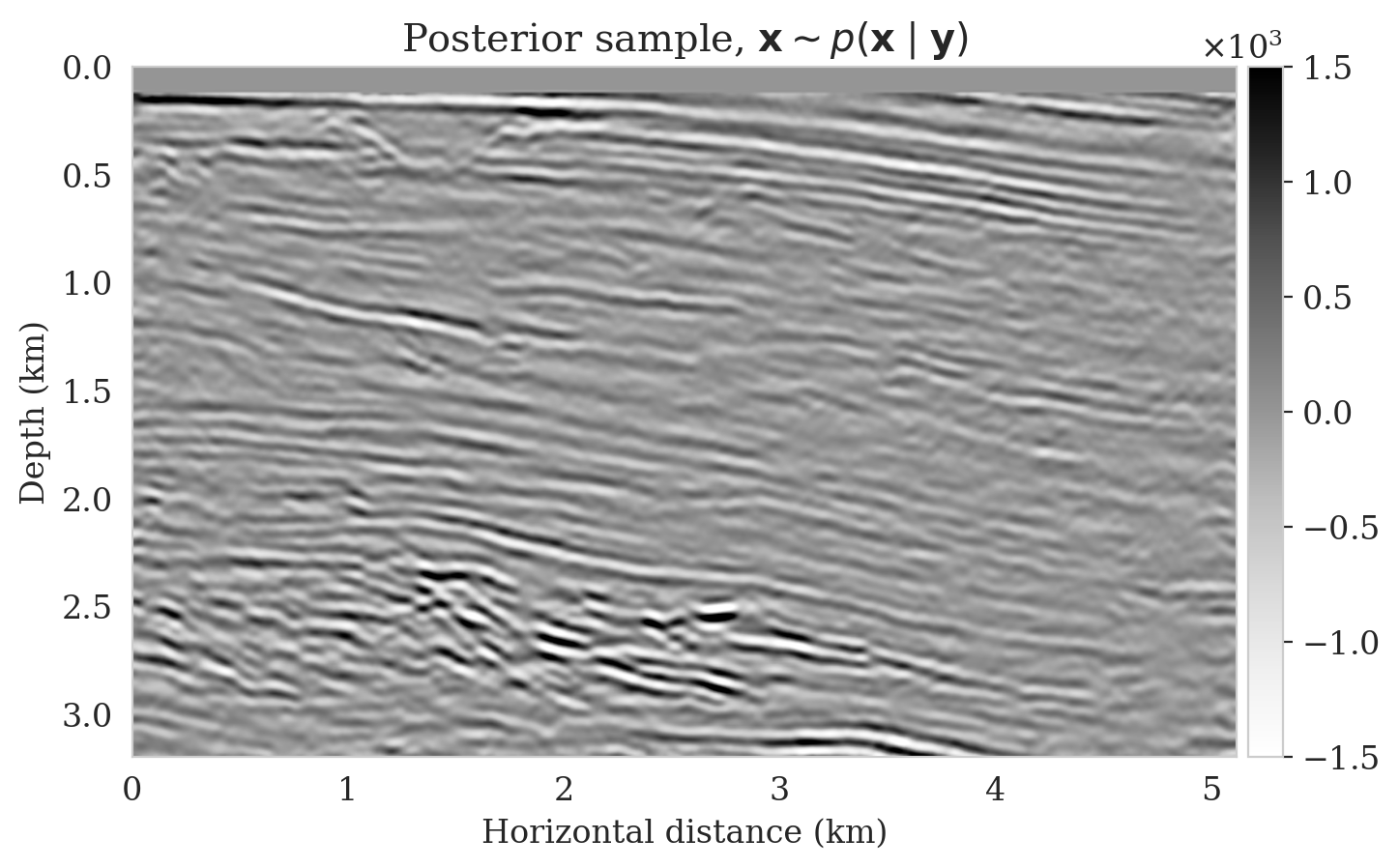
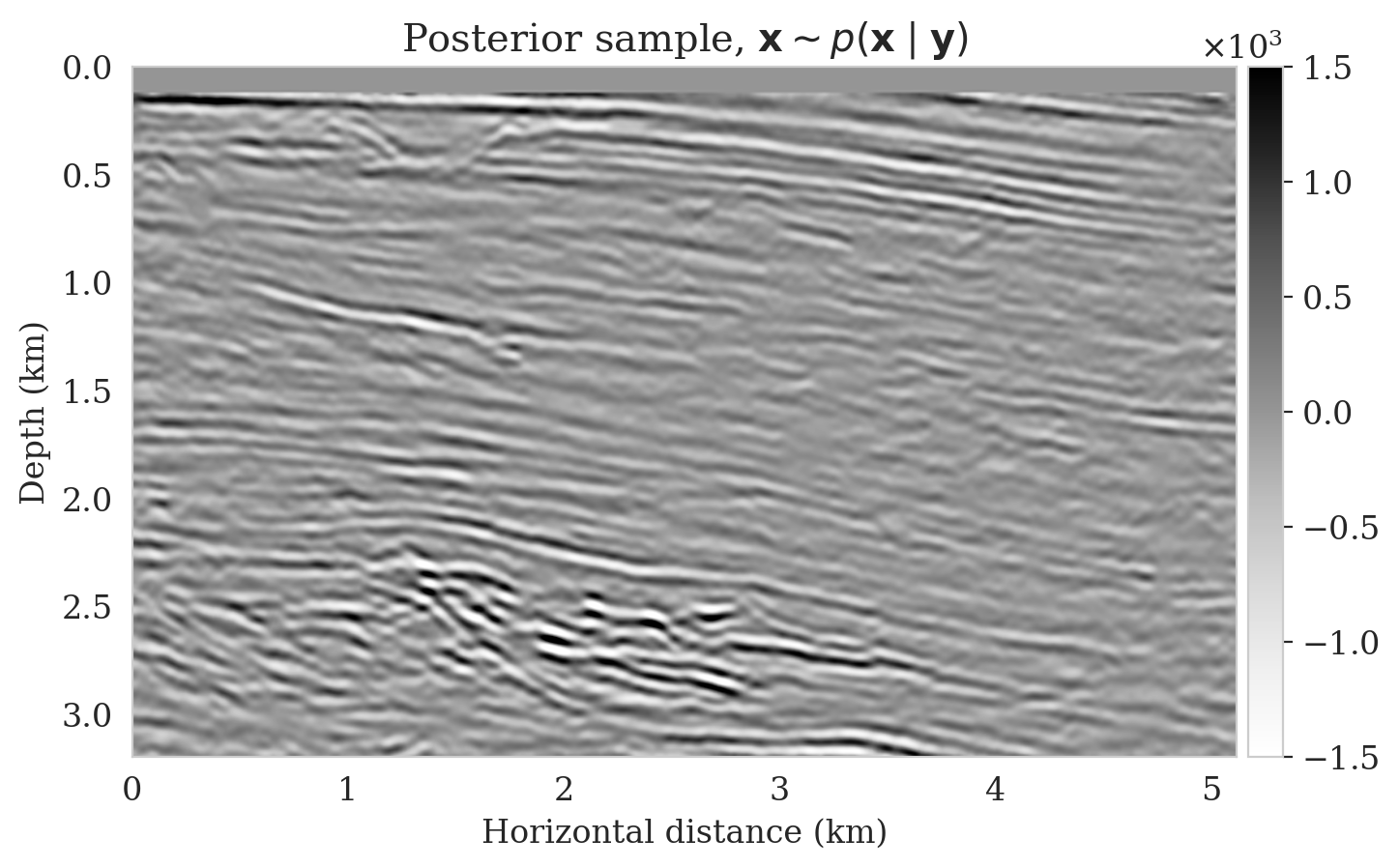
In this example, we use Devito (Luporini et al., 2018; M. Louboutin et al., 2019) for the wave-equation based simulations. For implementation of the network architectures, we rely on InvertibleNetworks.jl (P. Witte et al., 2021), a memory-efficient framework for training invertible nets in the Julia programming language. Finally, code to reproduce our results are made available on https://github.com/slimgroup/Software.SEG2021.
Conclusions and discussion
Seismic imaging is challenging due to complex and computationally expensive-to-evaluate forward operators and the highly heterogeneous multiscale structure of the Earth. These challenges limit the applicability of Markov Chain sampling methods due to the costs associated with the forward operator. These difficulties are compounded by difficulties in capturing the heterogeneity exhibited by the Earth’s subsurface in the form of a prior distribution. To handle this situation and to assess uncertainty, we propose a data-driven, conditional normalizing-flow based variational inference approach. The proposed inference scheme takes advantage of having access to training pairs—e.g., in form of high-fidelity seismic images and low-fidelity remigrated images, to train a conditional normalizing flow capable of sampling from the posterior distribution. Because neural nets are known to generalize, the trained conditional normalizing flow can be used to quickly generate samples from the posterior given unseen low-fidelity images. In turn, these samples provide access to the high-fidelity conditional mean estimate including a rudimentary assessment of its uncertainty. In that sense, the presented imaging scheme learns by example, maximally leveraging what is already known. Since we can not completely rely on generalization of neural nets, the trained conditional normalizing flow can be used as input to a second physics-based stage of inference where the normalizing flow undergoes transfer learning and then samples from the posterior specific to the imaging problem at hand. By means of a numerical example, we demonstrate that our proposed scheme indeed provides fast access to posterior samples for problems that would otherwise be computationally unfeasible to solve with the more traditional methods. Since the presented method relies on generalization by conditional normalizing flows, we stop short of claiming that we quantify uncertainty but rather that we supply a measure of reliability of the estimated image.
Acknowledgment
This research was carried out with the support of Georgia Research Alliance and partners of the ML4Seismic Center.
Adler, J., and Öktem, O., 2018, Deep Bayesian Inversion: ArXiv Preprint ArXiv:1811.05910.
Anderson, B. D., and Moore, J. B., 1979, Optimal Filtering: Prentice-Hall, Englewood Cliffs, NJ.
Arjovsky, M., Chintala, S., and Bottou, L., 2017, Wasserstein generative adversarial networks: In Proceedings of the 34th international conference on machine learning (Vol. 70, pp. 214–223). PMLR. Retrieved from http://proceedings.mlr.press/v70/arjovsky17a.html
Bishop, C. M., 2006, Pattern Recognition and Machine Learning: Springer-Verlag New York.
Blei, D. M., Kucukelbir, A., and McAuliffe, J. D., 2017, Variational inference: A review for statisticians: Journal of the American statistical Association, 112, 859–877.
Curtis, A., and Lomax, A., 2001, Prior information, sampling distributions, and the curse of dimensionality: Geophysics, 66, 372–378.
Dinh, L., Sohl-Dickstein, J., and Bengio, S., 2016, Density estimation using Real NVP: ArXiv Preprint ArXiv:1605.08803.
Fang, Z., Silva, C. D., Kuske, R., and Herrmann, F. J., 2018, Uncertainty quantification for inverse problems with weak partial-differential-equation constraints: GEOPHYSICS, 83, R629–R647. doi:10.1190/geo2017-0824.1
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … Bengio, Y., 2014, Generative Adversarial Nets: In Proceedings of the 27th international conference on neural information processing systems (pp. 2672–2680). Retrieved from http://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf
Herrmann, F. J., Siahkoohi, A., and Rizzuti, G., 2019, Learned imaging with constraints and uncertainty quantification: Neural Information Processing Systems (NeurIPS) 2019 Deep Inverse Workshop. Retrieved from https://arxiv.org/pdf/1909.06473.pdf
Jordan, M. I., Ghahramani, Z., Jaakkola, T. S., and Saul, L. K., 1999, An Introduction to Variational Methods for Graphical Models: Machine Learning, 37, 183–233. doi:10.1023/A:1007665907178
Kingma, D. P., and Ba, J., 2014, Adam: A Method for Stochastic Optimization: CoRR, abs/1412.6980.
Kotsi, M., Malcolm, A., and Ely, G., 2020, Uncertainty quantification in time-lapse seismic imaging: a full-waveform approach: Geophysical Journal International, 222, 1245–1263. doi:10.1093/gji/ggaa245
Kovachki, N., Baptista, R., Hosseini, B., and Marzouk, Y., 2020, Conditional Sampling With Monotone GANs: ArXiv Preprint ArXiv:2006.06755.
Kruse, J., Detommaso, G., Scheichl, R., and Köthe, U., 2019, HINT: Hierarchical Invertible Neural Transport for Density Estimation and Bayesian Inference: ArXiv Preprint ArXiv:1905.10687.
Lensink, K., Haber, E., and Peters, B., 2019, Fully Hyperbolic Convolutional Neural Networks:.
Liu, Q., 2017, Stein variational gradient descent as gradient flow: In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (Eds.), Advances in neural information processing systems (Vol. 30). Curran Associates, Inc. Retrieved from https://proceedings.neurips.cc/paper/2017/file/17ed8abedc255908be746d245e50263a-Paper.pdf
Louboutin, M., Lange, M., Luporini, F., Kukreja, N., Witte, P. A., Herrmann, F. J., … Gorman, G. J., 2019, Devito (v3.1.0): An embedded domain-specific language for finite differences and geophysical exploration: Geoscientific Model Development, 12, 1165–1187. doi:10.5194/gmd-12-1165-2019
Luporini, F., Lange, M., Louboutin, M., Kukreja, N., Hückelheim, J., Yount, C., … Gorman, G. J., 2018, Architecture and performance of devito, a system for automated stencil computation: CoRR, abs/1807.03032. Retrieved from http://arxiv.org/abs/1807.03032
Malinverno, A., and Briggs, V. A., 2004, Expanded uncertainty quantification in inverse problems: Hierarchical bayes and empirical bayes: GEOPHYSICS, 69, 1005–1016. doi:10.1190/1.1778243
Malinverno, A., and Parker, R. L., 2006, Two ways to quantify uncertainty in geophysical inverse problems: GEOPHYSICS, 71, W15–W27. doi:10.1190/1.2194516
Martin, J., Wilcox, L. C., Burstedde, C., and Ghattas, O., 2012, A Stochastic Newton MCMC Method for Large-scale Statistical Inverse Problems with Application to Seismic Inversion: SIAM Journal on Scientific Computing, 34, A1460–A1487. Retrieved from http://epubs.siam.org/doi/abs/10.1137/110845598
Marzouk, Y., Moselhy, T., Parno, M., and Spantini, A., 2016, Sampling via measure transport: An introduction: Handbook of Uncertainty Quantification, 1–41.
Mosser, L., Dubrule, O., and Blunt, M. J., 2020, Stochastic seismic waveform inversion using generative adversarial networks as a geological prior: Mathematical Geosciences, 52, 53–79. doi:10.1007/s11004-019-09832-6
Peters, B., and Haber, E., 2020, Fully reversible neural networks for large-scale 3D seismic horizon tracking: In 82nd eAGE annual conference & exhibition (pp. 1–5). European Association of Geoscientists & Engineers.
Putzky, P., and Welling, M., 2019, Invert to learn to invert: In H. Wallach, H. Larochelle, A. Beygelzimer, F. dAlché-Buc, E. Fox, & R. Garnett (Eds.), Advances in neural information processing systems (Vol. 32). Curran Associates, Inc. Retrieved from https://proceedings.neurips.cc/paper/2019/file/ac1dd209cbcc5e5d1c6e28598e8cbbe8-Paper.pdf
Ray, A., Kaplan, S., Washbourne, J., and Albertin, U., 2017, Low frequency full waveform seismic inversion within a tree based Bayesian framework: Geophysical Journal International, 212, 522–542. doi:10.1093/gji/ggx428
Rezende, D., and Mohamed, S., 2015, Variational Inference with Normalizing Flows: In Proceedings of the 32nd International Conference on Machine Learning (Vol. 37, pp. 1530–1538). PMLR. Retrieved from http://proceedings.mlr.press/v37/rezende15.html
Rizzuti, G., Siahkoohi, A., Witte, P. A., and Herrmann, F. J., 2020, Parameterizing uncertainty by deep invertible networks, an application to reservoir characterization: SEG Technical Program Expanded Abstracts. doi:10.1190/segam2020-3428150.1
Robert, C., and Casella, G., 2004, Monte Carlo statistical methods: Springer-Verlag.
Siahkoohi, A., Rizzuti, G., and Herrmann, F. J., 2020, A deep-learning based bayesian approach to seismic imaging and uncertainty quantification: 82nd EAGE Conference and Exhibition 2020. Retrieved from https://slim.gatech.edu/Publications/Public/Submitted/2020/siahkoohi2020EAGEdlb/siahkoohi2020EAGEdlb.html
Siahkoohi, A., Rizzuti, G., and Herrmann, F. J., 2020a, Uncertainty quantification in imaging and automatic horizon tracking—a Bayesian deep-prior based approach: SEG technical program expanded abstracts 2020. doi:10.1190/segam2020-3417560.1
Siahkoohi, A., Rizzuti, G., Louboutin, M., Witte, P., and Herrmann, F. J., 2021, Preconditioned training of normalizing flows for variational inference in inverse problems: 3rd Symposium on Advances in Approximate Bayesian Inference. Retrieved from https://openreview.net/pdf?id=P9m1sMaNQ8T
Siahkoohi, A., Rizzuti, G., Witte, P. A., and Herrmann, F. J., 2020b, Faster uncertainty quantification for inverse problems with conditional normalizing flows: No. TR-CSE-2020-2. Georgia Institute of Technology. Retrieved from https://arxiv.org/abs/2007.07985
Stuart, G. K., Minkoff, S. E., and Pereira, F., 2019, A two-stage Markov chain Monte Carlo method for seismic inversion and uncertainty quantification: GEOPHYSICS, 84, R1003–R1020. doi:10.1190/geo2018-0893.1
Tarantola, A., 2005, Inverse problem theory and methods for model parameter estimation: SIAM. doi:10.1137/1.9780898717921
Villani, C., 2009, Optimal transport: old and new: Springer-Verlag Berlin Heidelberg. doi:10.1007/978-3-540-71050-9
Welling, M., and Teh, Y. W., 2011, Bayesian Learning via Stochastic Gradient Langevin Dynamics: In Proceedings of the 28th International Conference on Machine Learning (pp. 681–688). Omnipress. doi:10.5555/3104482.3104568
WesternGeco., 2012, Parihaka 3D PSTM Final Processing Report: No. New Zealand Petroleum Report 4582. New Zealand Petroleum & Minerals, Wellington.
Witte, P., Rizzuti, G., Louboutin, M., Siahkoohi, A., Herrmann, F., and Peters, B., 2021, InvertibleNetworks.jl: A Julia framework for invertible neural networks (Version v2.0.0). Zenodo. doi:10.5281/zenodo.4610118
Zhang, X., and Curtis, A., 2020a, Seismic tomography using variational inference methods: Journal of Geophysical Research: Solid Earth, 125, e2019JB018589.
Zhang, X., and Curtis, A., 2020b, Variational full-waveform inversion: Geophysical Journal International, 222, 406–411. doi:10.1093/gji/ggaa170
Zhao, X., Curtis, A., and Zhang, X., 2020, Bayesian seismic tomography using normalizing flows:. doi:10.31223/X53K6G
Zhao, Z., and Sen, M. K., 2019, A gradient based MCMC method for FWI and uncertainty analysis: SEG Technical Program Expanded Abstracts 2019. doi:10.1190/segam2019-3216560.1